Абсолютно все сеошники сталкиваются с разработкой и настройкой robots.txt. Грамотно составленный документ позволяет быстрее индексировать страницы и занимать высокие позиции в выдаче по релевантным запросам. Мы написали простую инструкцию для начинающих SEO-специалистов: о том, что из себя представляет индексный файл и как его правильно настраивать.
Файл robots.txt — текстовый документ в кодировке UTF-8, ограничивающий краулерам доступ к контенту (разделам, страницам) вебсайта. Действует по протоколам URL (http, https и FTP).
В основном он нужен, чтобы:
От индексации обычно закрывают панель администратора, результаты поиска по сайту, страницы регистрации и авторизации, фиды, пустые или разрабатываемые страницы и т.д.
Краулинговый бюджет — предел страниц для сканирования поисковыми роботами за интервал времени. Расчёт производится с учетом пользовательского спроса и доступности сервера.
Иногда вместо индексного файла применяют noindex в мета-теге robots. Например, чтобы передать ссылочный вес страницы, убираемой из индекса. Добавляем в <head> мета-тег <meta name=”robots” content=”noindex, follow”>.
Важно: директивы robots.txt и инструкция noindex в robots выступают как рекомендации и могут быть проигнорированы роботами.
Перед тем, как приступать к созданию файла, необходимо убедиться в отсутствии robots.txt на сайте. Самый простой способ узнать о наличии такого файла — поместить URL-адрес сайта в браузер с добавлением /robots.txt. В результате произойдет одно из трёх событий:
Краткое руководство по созданию:
Необходимо ознакомиться с инструкциями по наполнению, директивами и синтаксисом файла.
Таким образом, хотя файл `robots.txt` и мета-тег `noindex` являются важными инструментами для управления доступом краулеров к контенту сайта, они не гарантируют полную защиту от индексации. Поэтому для более надежной защиты конфиденциальной информации стоит использовать более строгие методы, такие как аутентификация пользователя, SSL-шифрование и правильная настройка сервера.
Дополнительно, для контроля над процессом индексации можно использовать Google Search Console и аналогичные инструменты вебмастера от других поисковых систем. Эти платформы позволяют не только мониторить статус индексации страниц, но и отправлять запросы на повторное сканирование измененных или новых страниц, что способствует более точному и актуальному отображению контента в поисковой выдаче.
Кроме того, важно регулярно проверять и обновлять файл `robots.txt`, чтобы убедиться, что директивы соответствуют текущим целям SEO и веб-безопасности. Неправильно настроенный файл `robots.txt` может случайно блокировать важные страницы от индексации или, наоборот, допускать сканирование страниц, которые не должны быть доступны широкой публике.
Обращаем внимание, что для вебсайтов с поддоменами для каждого в корне указываются отдельные robots.txt.
Директивы прописывают инструкции для поисковых роботов. Каждая указывается с новой строки. Рассмотрим их назначение и особенности:
1. Обязательная директива User-agent. С ее помощью задаем правила для каждого робота:
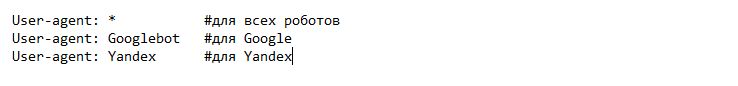
Поисковики выбирают специфичные (подходящие для них) правила и могут проигнорировать инструкции в *. Поэтому рекомендуется прописывать несколько агентов для каждого, разделяя наборы разрывом строки.
2-3. Allow и Disallow регулируют доступ к контенту для индексирования. Первая директива открывает, вторая — закрывает. Использование слэша (/) — останавливает краулеров от сканирования содержимого сайта: Disallow: /
Однако Disallow с пустой секцией равнозначен Allow.
Рассмотрим частный случай:

В таком сочетании роботы просматривают только определенный пост блога, остальной контент для них недоступен.
4. Sitemap — прописывает положение карты сайта в xml формате. Такая навигация содержит URL страниц, обязательных к индексации. После каждого обхода роботом получим обновление информации о сайте в поиске с учетом всех изменений в файле.
Пример: Sitemap: https://site.com//sitemap.xml.
5. Clean-param применяется дополнительно и действует для Яндекса.
Исключает динамические (UTM-метки) и get-параметры. Такие данные не влияют на содержимое страницы, следовательно, недопустимы к индексации.
Через «&» указываются параметры, после — префикс пути всех или отдельных страниц, к которым применяется правило:
Clean-param: parm1&parm2&parm3/
Clean-param: parm1&parm2&parm3/page.html
При наличии нескольких страниц с дублирующейся информацией целесообразнее свести их адреса к одному:
Clean-param: ref /some_dir/get_products.pl — содержит адреса страниц:
www.robot.com/some_dir/get_products.pl?products_id=123
www.robot.com/some_dir/get_products.pl?ref=site_1&products_id=123
www.robot.com/some_dir/get_products.pl?ref=site_2&products_id=123
www.robot.com/some_dir/get_products.pl?ref=site_3&products_id=123
Параметр ref используем, чтобы отследить ресурс, с которого поступил запрос.
6. Craw-delay определяет время для обхода страниц.
Пример: Crawl-delay: 2 — интервал в 2 секунды.
7. Через Host указываем главное зеркало сайта, чтобы избежать дублей в выдаче. При наличии нескольких значений учитывается только первое, остальные игнорируются.
Краулеры по-разному интерпретируют директивы. Яндекс соблюдает правила, описанные в файле. Google руководствуется собственными принципами. Поэтому при работе с ним рекомендуется закрывать страницы через мета-тег robots.
Спецсимволы «/, *, $, #»
Звездочка (*) учитывает последовательность символов. Символ $ сообщает об окончании строки и нейтрализует звездочку (*).

После решетки «#» размещаем комментарии в той же строке. Их содержание игнорируется при сканировании.
Слэш «/» скрывает контент. Один слэш в Disallow не допускает к индексации весь сайт. Два знака «//» применяются для запрета на сканирование отдельной директории.
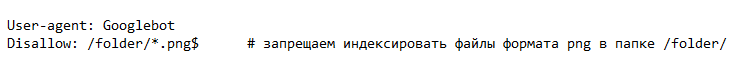
Собираем данные, определяем нужные и «мусорные» страницы. С их учётом наполняем документ, не забывая про требования и инструкции. В итоге получаем готовый robots.txt вида:

Открываем доступ к стилям и скриптам для корректного проведения рендеринга. В противном случае не удастся правильно проиндексировать содержимое, что отрицательно отразится на позиции сайта.
Внедряем Clean-param при наличии динамических ссылок или передаче параметров в URL. Использование Craw-Delay также необязательно и вступает в силу в случае нагрузки на ресурс.
Полное ограничение доступа краулерам — самая большая ошибка в использовании индексного файла. Поисковые системы перестанут сканировать ресурс, что может отрицательно отразиться на органическом трафике. Рекомендуем только дополнять и обновлять файл после тестирования каждого внесенного правила для своевременного исправления ошибок. При создании и внесении изменений в robots.txt применяем золотое правило: меньше строк, больше смысла.
В случае отказа от внедрения индексного файла краулеры будут сканировать ресурс без ограничений. При этом отсутствие такого файла не критично для малых сайтов. В противном случае, следует учитывать краулинговый бюджет и внедрять документ robots.
Важно: robots.txt — общедоступный файл. Пока существует вероятность индексации закрытого контента необходимо убедиться, что страницы с конфиденциальной информацией используют пароли и noindex.
Чтобы предотвратить неэффективное использование краулингового бюджета, важно четко указать, какие разделы сайта должны быть проиндексированы, а какие — нет. Это особенно критично для больших сайтов с множеством страниц, где необходимо оптимизировать процесс сканирования контента. Используя директивы Allow и Disallow в файле robots.txt, можно эффективно управлять доступом краулеров к различным частям сайта.
Перед внесением любых изменений в файл robots.txt крайне важно проводить их тестирование с помощью специализированных инструментов, таких как Google Search Console. Это позволяет убедиться, что изменения не повлияют на индексацию важных страниц и не ограничат доступ краулеров к ключевому контенту. Регулярный аудит файла также помогает избежать ошибок, которые могут привести к потере трафика.
Особое внимание стоит уделить исключениям в файле robots.txt. Исключение ненужных к индексации файлов и директорий помогает сократить нагрузку на сервер и улучшить скорость обработки сайта поисковыми системами. Однако необходимо четко понимать, какие ресурсы критически важны для SEO, чтобы не исключить их случайно из процесса сканирования.
Дополнительное внимание должно быть уделено защите конфиденциальной информации. Необходимо использовать механизмы аутентификации и директивы noindex для страниц, содержание которых не предназначено для публичного доступа или индексации. Это предотвратит случайное попадание чувствительных данных в поисковые системы, даже если они будут доступны через файл robots.txt.
В условиях постоянно изменяющихся алгоритмов поисковых систем и динамично развивающегося контента, необходимо регулярно пересматривать и адаптировать файл robots.txt. Обновление файла в соответствии с текущими требованиями и добавление новых директив в ответ на изменения в структуре сайта или стратегии контента поможет поддерживать оптимальную видимость в поисковых системах.
Наконец, помните о защите конфиденциальной информации. Несмотря на то, что файл robots.txt не гарантирует полной защиты от индексации, его правильная настройка в сочетании с другими методами, такими как использование мета-тегов noindex и аутентификации пользователей, поможет минимизировать риски утечки данных.
Применение этих подходов к управлению файлом robots.txt позволит не только улучшить SEO-позиции сайта, но и обеспечить более качественное и целенаправленное индексирование контента, учитывая потребности и особенности вашего веб-ресурса.

Павел Лапаревич, SEO-специалист GUSAROV:
Гугл уже давно воспринимает robots.txt как рекомендацию и спокойно индексирует страницы с параметрами и служебные страницы сайта (страницы регистрации, авторизации, корзины и т.д.). Смысла от прописывания директив и траты времени на него становится всё меньше. Более действенный способ настройки: вывод <meta name=»robots» content=»noindex»>. Страницы с таким мета тегом в robots.txt не закрываются. Но все же есть преимущество этого файла над noindex. Краулеры перестают переобходить страницы, закрытые в robots.txt, а, следовательно, экономится краулинговый бюджет. Поэтому для больших сайтов лучше использовать robots.txt и постоянно следить за индексом, закрывая страницы, которые поисковики продолжают индексировать с помощью noindex.
 Канал Андрея Гусарова
Канал Андрея ГусароваПодпишись на регулярный текст от босса и маркетолога. Здесь никогда не будет скучной информации.
Присоединиться
Вы долистали до подвала, вы терпеливый товарищ,
давайте мы ответим на ваши вопросы по телефону


